
因为今年疫情原因,项目组的资源需要优化调整,整体目标是此次测试环境和准生产环境的资源降低三分之一。
1 jvm 层面压缩资源
目前的模块 Docker 打包部分:

经过服务启动时的资源检控与压力测试,确定大部分的服务其实 512m 内存完全是足够用的,只有部分并发量较大的服务使用了 1g 内存。
所以二话不说,直接将 docker 镜像中的资源默认为一个较低的数值:

由于这个 JAVA_OPTS 是可以使用环境变量来覆盖的,所以在准生产环境可以将这个变量统一由 configmap 来覆盖掉,某些资源要求额外较高的可以在 pod 描述文件中再次覆盖,优先级为 docker<configmap<yml

global-configmap 中有一个用来覆盖 docker 中此变量的值

这种覆盖的思路可以灵活的将某些并发较大需求资源较多的模块在 jvm 层面扩充资源,并且大部分需求不高的模块依然走默认的较低资源配置。
2 pod 层面优化资源分配
在 pod 的配置文件中有两个资源相关配置,limit 和 requests
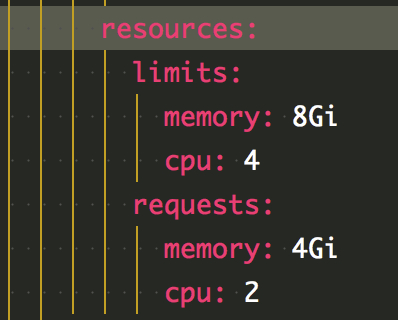
官方文档描述 request 为 pod 默认的资源占用,limit 为最大资源占用。
直接将资源降低到与 jvm 相近的配置
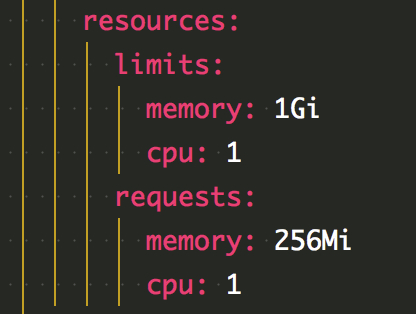
这时坑来了,更新配置后 pod 不断重启。
经过不断修改内存和 CPU 占用尝试发现导致重启的原因不是内存,而是 limits 中的 CPU 核数。
关于 limits 中 CPU 核数,但实际观察中发现,request 的 CPU 核数分配给这个 pod 的时候,有个类似于计数器的逻辑将这个数量的 CPU 核数占住,其他的 pod 再申请的时候是不会释放的,也就是说如果集群总共有 64 个核,那么如果每个 pod 的 requests 中声明了 4 个,启动第 17 个 pod 的时候会发生 CPU 资源不够用,官方文档有说明,所有 pods 的总 limitscpu 个数是可以超过物理 CPU 个数的,但是如果每个 pod 限制的 CPU 个数过低会发生无法启动 pod 等问题。实际的 limits 个数应该根据程序峰值时的用量和低谷时用量来设置。如果 requestscpu 设置的过高,pod 一直为 pending 状态,但是查看集群的整体资源占用情况时,CPU 整理利用率仅为 2% 左右。
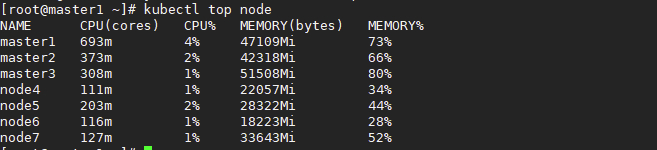
所以此时参考 kube-system 中官方 pod 尝试将 limits 部分的限制去掉,让物理机中的所有 pod 去竞争 CPU 资源。同时将 request 中的声明资源进一步压缩。
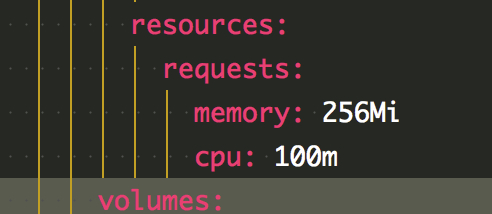
执行 apply 后 所有 pod 稳定启动,经过观察去除掉了 4cpu 限制后出现了这样的场景:
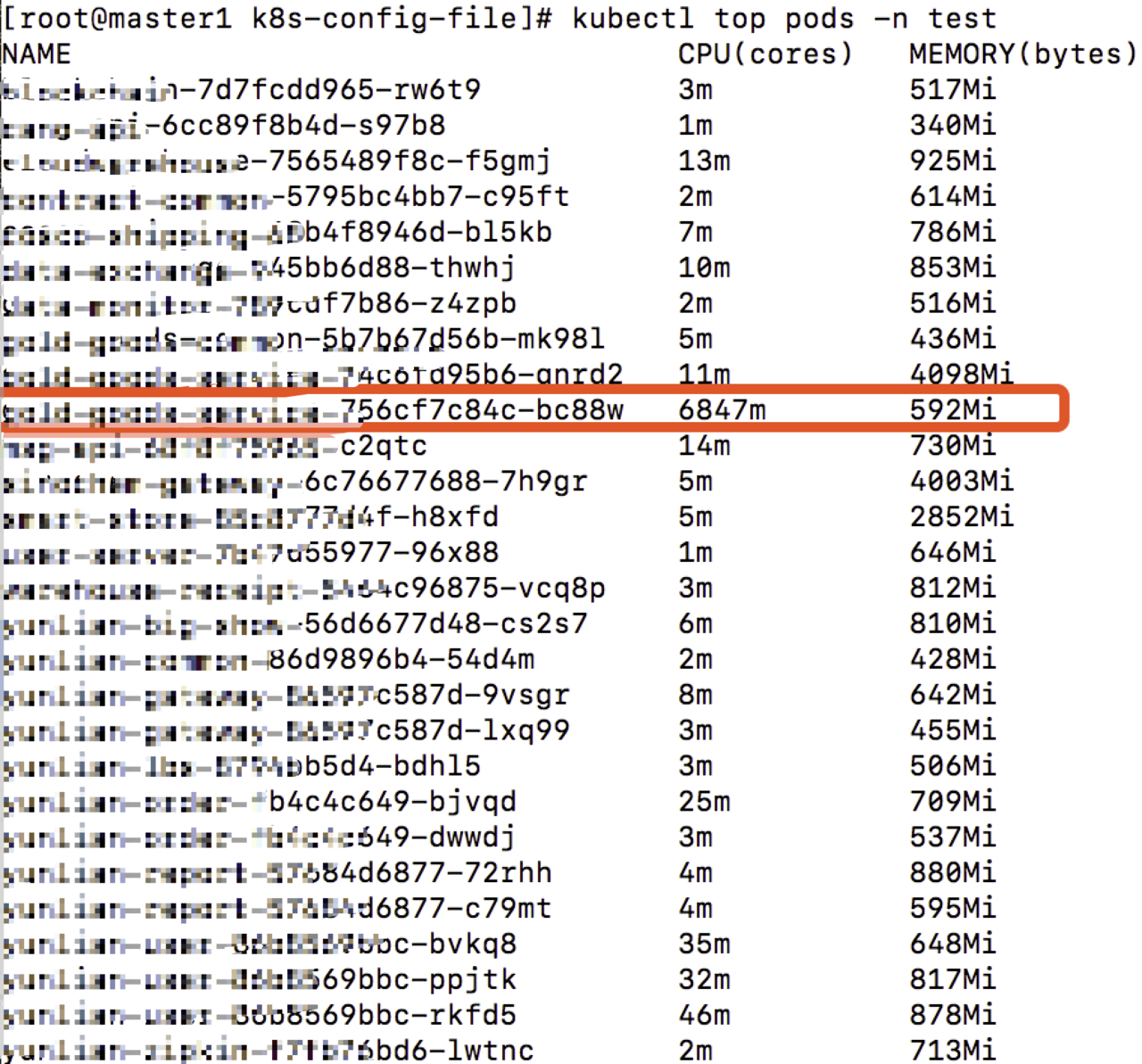
有一些 pod 在启动过程中竟然瞬时 CPU 占用接近 7 核,这也验证了之前的猜测,大部分模块只是启动时瞬时占用较高,稳定运行时甚至并发量较高时都不会太高。当启动时触发到了 limits 中的限制会强行重启。
至于真正大批量到达高峰时的资源限制还是要做,但是得实际根据压测情况动态去配置了。
至此 所有资源使用仅为之前的五分之一,超额完成了缩容任务,后续再继续配合运维同学去将机器减配重启。
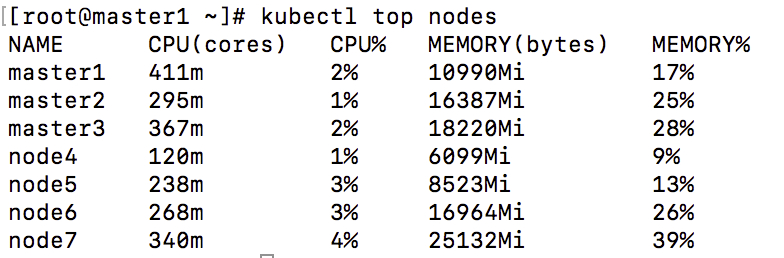
具体的 limits 数量应该根据运行一段时间和压测的实际占用量来设置。